Enterprise AI Strategy | | 24 min read
Measuring Enterprise AI ROI in Mission Critical Environments

Key Takeaways
AI ROI has to be designed before the pilot starts
No baseline, no ROI
If the team never records the before state, the after state becomes an opinion instead of a return calculation.
Activity is not value
Prompts, logins, and usage reports do not prove impact. ROI shows up in workflow cost, speed, quality, risk, capacity, and revenue support.
Measure the portfolio
A disciplined AI program scales what proves value, redesigns what is close, and stops pilots that cannot meet the metric.
Most enterprise AI spending cannot prove it earned anything, and not because the AI did not work.
The problem is usually more basic. Nobody captured a baseline before the pilot started. Nobody tied the use case to a metric that maps to the P&L. Nobody owned the outcome instead of the launch. Nobody counted the full cost of running the system, only the license.
By the time someone asks, "what did we get for this?", the question is hard to answer because the evidence that would answer it was never collected.
That is the trap. Measuring AI ROI is not a spreadsheet you build after the fact. It is a discipline you design into the work before the pilot: pick the metric, capture the baseline, assign the owner, count the full cost, redesign the workflow, measure the same metric, then decide what scales and what stops.

Spending on AI but unable to prove the return?
GS Consulting helps CIOs, operations leaders, and executives measure enterprise AI ROI with baseline capture, P&L linked metrics, full cost models, workflow redesign, and evidence a CFO can inspect.
Request an AI ROI Measurement AssessmentWhy AI ROI Goes Unmeasured
The failure to show return has specific causes. GS Consulting scored the reasons enterprise AI spend most often fails to demonstrate measurable return.
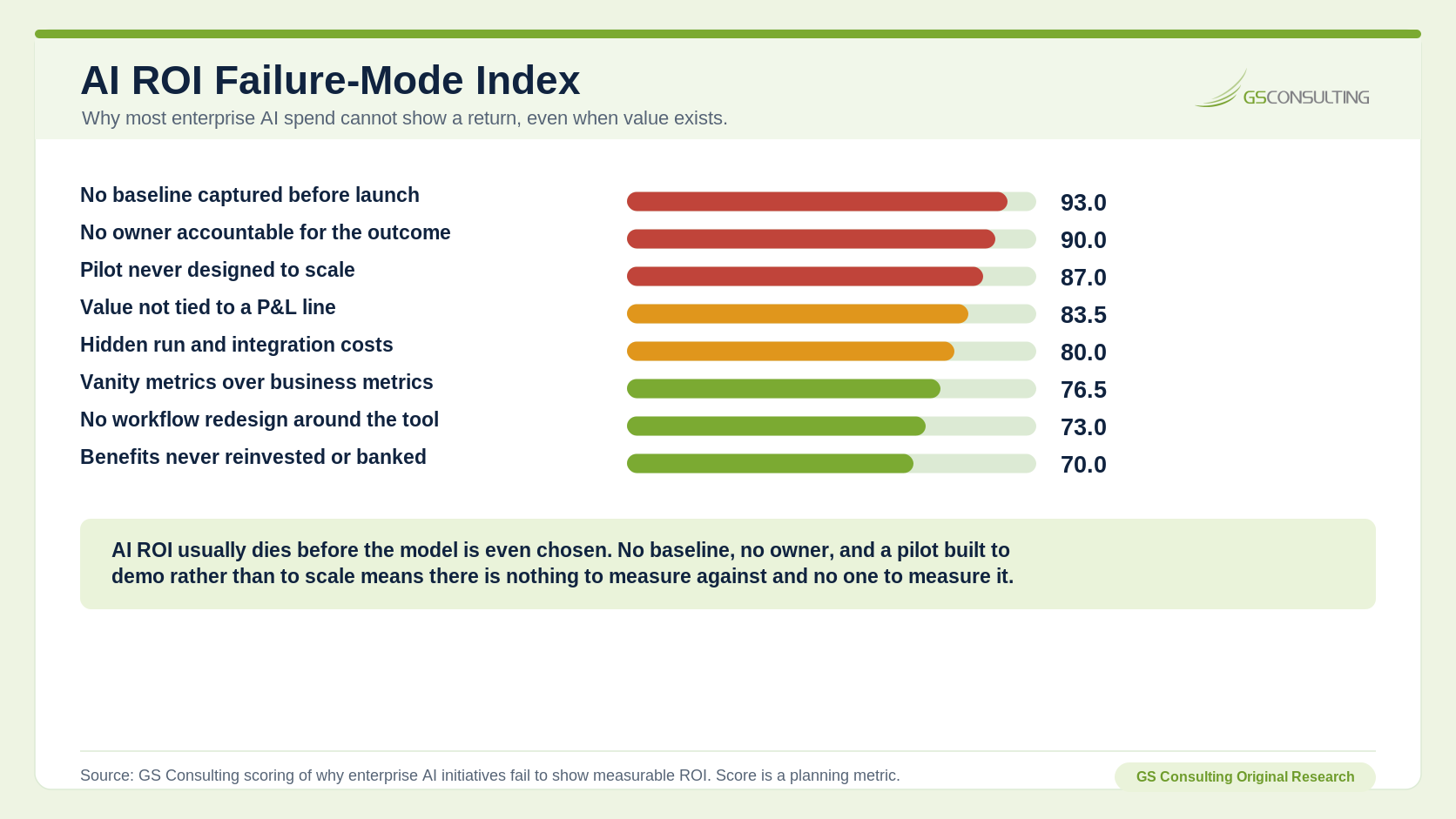
No baseline ranks first because it is fatal and irreversible. If you did not measure the before state, no amount of after measurement can create a credible return.
No accountable owner ranks second because value does not capture itself. A pilot can create useful output and still fail financially if nobody is responsible for banking or redeploying the value.
A pilot never designed to scale ranks third because a demo that works once tells leaders very little about production cost, production volume, support burden, integration, data quality, and user adoption.
The AI ROI Failure Mode Index is a GS Consulting derived planning metric. It is not a financial audit or benchmark of any specific organization.
Where the Return Actually Shows Up
When AI pays off, the return appears in specific places, not in a vague sense that the organization is becoming more modern.
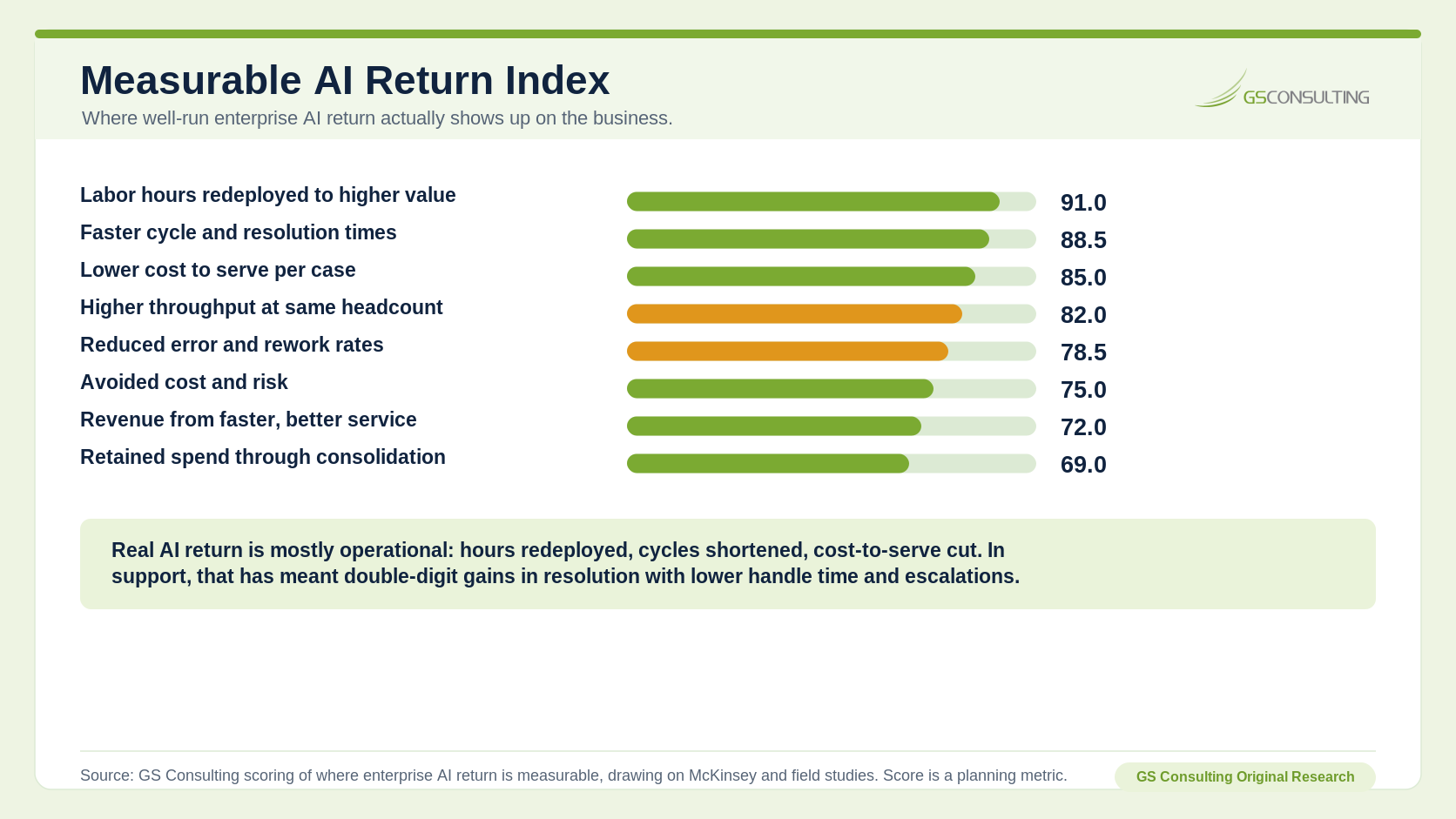
The clearest return is labor hours redeployed to higher value work. AI rarely shows up first as headcount removed. It shows up as the same people spending less time on low value work and more time on work that actually moves the mission or business.
Faster cycle and resolution times are also strong because they are observable and translate cleanly into capacity and service outcomes. Lower cost to serve per case turns the operational improvement into a number a CFO recognizes.
Notice the common thread. Every one of these value paths requires a before number. "People are using the tool" is not ROI. "The task that used to take forty minutes now takes twelve, at the same or better quality, with known review cost" is the start of ROI.
The Wrong Way to Measure AI ROI
The wrong way is to launch first and look for the return later.
A team gets budget because AI is clearly important. They pick a promising use case and stand up a pilot quickly. They do not record how the work was done before, how long it took, how often it failed, or what it cost because that feels like paperwork slowing down momentum.
The pilot runs. People like it. Usage metrics look good. Then the funding review arrives and someone asks for ROI. Now the team is reverse engineering a return from memory, guessing at a baseline, and presenting activity metrics as business impact.
The CFO is skeptical, and the CFO is right. "People used it a lot" is not a return. It is a usage report.
That is how useful pilots become unfundable. The AI may have helped. The organization simply made the help impossible to prove.
The Right Way: Design the Return Before the Pilot
The right way treats ROI as something engineered into the use case before launch, with gates that force the measurement decisions up front.

- Gate 1Pick the metric.
Define the business outcome the use case is supposed to move: hours, cost per case, cycle time, error rate, backlog, throughput, or risk reduction.
- Gate 2Capture the baseline.
Measure the metric as it stands today before AI touches the work.
- Gate 3Assign an owner.
Make one accountable person responsible for the outcome, not just the launch.
- Gate 4Count the full cost.
Include license, integration, data, security, governance, review time, support, and run cost at scale.
- Gate 5Redesign the workflow.
Change the work around the AI so value can be captured, not just demonstrated.
- Gate 6Measure against baseline.
Measure the exact same metric the same way after launch.
- Gate 7Bank the benefit.
Redeploy hours, reduce cost, increase capacity, cut backlog, or book the savings in a way leadership can see.
- Gate 8Decide scale or stop.
Scale what meets the evidence threshold. Redesign or stop what does not.
A Little Math on the Cost of Not Measuring
The cost of skipping measurement hides as opportunity cost.
Picture an organization running ten AI use cases without baselines or owners. Suppose half are genuinely creating value and half are not. Because none were measured, leadership cannot tell which half is which.
So the organization does the worst possible thing with the portfolio. It keeps funding all ten because no one can prove any single one should stop, and it scales none of them confidently because no one can prove any single one deserves more money.
The five winners never get the investment that would multiply their return. The five losers keep drawing budget and attention. The measurement that would have cost a small amount of setup per use case would have let the organization stop five, scale five, and put the same spend behind what works.
That is the financial case for measurement. It is not overhead. It is how leaders manage AI as a portfolio instead of a pile of unkillable pilots.
ROI Disciplines, Ranked
Measuring AI ROI is a set of disciplines, and they are not equally decisive. GS Consulting scored the major disciplines on how reliably they turn AI spend into provable return, how feasible they are, and how durable the benefit is.

The highest scoring discipline is capturing a baseline before every pilot. It is the precondition for any ROI claim and the one step that cannot be recovered later.
Tying each use case to a P&L linked metric ranks just below because it separates business impact from activity counts. Assigning an accountable owner rounds out the top tier because value that nobody owns rarely gets captured.
The Enterprise AI ROI Decision Matrix is a GS Consulting derived planning model, not a financial determination.
The Evidence: What Measurement Produces
In a mission critical environment, a claimed return that cannot be shown will not get funded. GS Consulting frames the output of ROI work as an evidence packet because that is what a CFO, board, or executive sponsor will need before releasing the next tranche of AI spend.

This packet shows the expected outcome, the metric, the before number, the full cost, the owner, how the work changed, the after number, the benefit actually banked, and the return per dollar. That is what makes the scale or stop decision defensible.
If you can produce this for a use case, the next funding conversation gets much easier. If you cannot produce the baseline and realized benefit, you do not have a return to claim. You have a story.
The First 90 Days
- Days 1 to 14Inventory active AI use cases.
Identify current pilots, owners, costs, workflows, users, data, risk level, and whether a baseline exists.
- Weeks 3 to 6Define metrics and owners.
Choose one P&L linked metric for each use case worth keeping, assign an outcome owner, and build an honest full cost model.
- Week 7Redesign priority workflows.
Change the highest potential workflows so AI removes work, improves review, reduces delay, or creates measurable capacity.
- Weeks 8 to 13Measure and decide.
Compare results against the baseline, bank or redeploy the value, and make the first scale, redesign, or stop decisions.
Ninety days will not give you a fully instrumented AI portfolio. It should give leadership a credible return number on the strongest use cases, a defensible reason to stop weak ones, and a repeatable measurement model for what comes next.
Common Mistakes
- Launching pilots without a baseline. That makes ROI impossible from the start.
- Measuring activity instead of outcomes. Prompts, logins, and active users do not prove business impact.
- Counting the license and ignoring full cost. Integration, data, review, security, governance, and operations can change the return fast.
- Leaving the old workflow untouched. AI value is captured when the work changes, not when a tool is added to the same steps.
- Never banking the benefit. Efficiency that is not redeployed, booked, or used to increase capacity stays theoretical.
How This Fits a Secure Enterprise AI Strategy
ROI measurement is what keeps a Secure Enterprise AI Strategy honest. The strategy decides which AI capabilities to pursue and how to govern them. Measurement tells leaders whether those bets are actually paying off.
This page owns one specific question: how do leaders prove enterprise AI return in a way a CFO, board, or mission sponsor can trust?
That question connects directly to Building the Business Case for Secure Enterprise AI, Total Cost of Ownership for Secure Enterprise AI, Shifting from Point Solutions to Unified AI Platforms, Developing a Phased Secure AI Adoption Roadmap, Managing Change and Adoption in Secure AI Rollouts, Enterprise AI Readiness Assessment, AI ROI Calculation for Enterprise Leaders, Enterprise AI Governance Frameworks for GovCon, Establishing Guardrails for Enterprise Generative AI, and Managing AI Vendor Risk in Regulated Industries.
The Bottom Line
The reason enterprise AI spend often cannot prove return is not that AI failed. It is that the organization skipped the conditions that make return measurable: baseline, metric, owner, full cost model, workflow redesign, and evidence.
By the time leaders ask what the spend bought, the before number is gone. The team is left with anecdotes, usage reports, and estimates from memory.
Design the return before the model. Capture the baseline before the pilot. Measure the same metric after launch. Bank the benefit. Scale what works and stop what does not. That is how AI becomes a portfolio leaders can manage instead of a budget line they have to defend on hope.
Ready to turn AI spend into a return you can defend?
GS Consulting helps CIOs, operations leaders, and executives measure enterprise AI ROI from baseline capture and P&L linked metrics through full cost modeling, workflow redesign, and funding evidence.
Request an AI ROI Measurement AssessmentResearch Sources and Caveats
This article draws on public 2024 through 2026 sources on enterprise AI returns, including MIT NANDA project findings on generative AI pilot impact as reported in business press, Gartner data on generative AI project abandonment after proof of concept, McKinsey State of AI research on high performers and EBIT impact, Wavestone survey data on AI ROI frameworks, GAO reporting on federal AI use case growth, and field studies of AI assisted customer support productivity associated with McKinsey and academic researchers.
The AI ROI Failure Mode Index, Measurable AI Return Index, and Enterprise AI ROI Decision Matrix are GS Consulting derived planning tools. They are not financial audits, guaranteed outcomes, or benchmarks of any specific organization. Pilot failure rates, abandonment rates, and productivity figures reflect specific source methodologies and should be treated as directional benchmarks. Nothing here is financial advice.
Frequently Asked Questions About Measuring Enterprise AI ROI
Why do so many AI pilots show no ROI if the technology works?
Many AI pilots show no ROI because the return was never designed to be measured. The organization did not capture a baseline, tie the use case to a business metric, assign an outcome owner, count full cost, or define how value would be banked. The AI may help, but the proof is missing.
What is the most important step in measuring enterprise AI ROI?
The most important step is capturing a baseline before the pilot starts. Leaders need to know how long the workflow takes, what it costs, how often errors occur, and what volume exists today. Without that before number, the after number has nothing credible to compare against.
Should enterprise AI ROI be measured by headcount reduction?
Usually no. Most enterprise AI return appears as redeployed labor hours, faster cycle time, lower cost to serve, higher throughput, fewer errors, and avoided risk. Headcount reduction is only one possible value path, and treating it as the default can weaken adoption and distort the business case.
How long should an AI pilot run before leaders decide whether to scale it?
The measurement window should be defined before launch. Many operational pilots can produce useful evidence within 90 to 180 days if the baseline, metric, owner, full cost model, and workflow changes are already in place. The decision should be scale, redesign, or stop based on the agreed evidence.
Related Reading
- Secure Enterprise AI Strategy
- Building the Business Case for Secure Enterprise AI
- Total Cost of Ownership for Secure Enterprise AI
- Shifting from Point Solutions to Unified AI Platforms
- Developing a Phased Secure AI Adoption Roadmap
- Establishing Guardrails for Enterprise Generative AI
- Managing Change and Adoption in Secure AI Rollouts
- Enterprise AI Readiness Assessment
- AI ROI Calculation for Enterprise Leaders
- Managing AI Vendor Risk in Regulated Industries