Secure AI Automation | | 26 min read
Secure RAG Architecture for GovCon

Key Takeaways
AI adoption has to move fast and stay controlled.
Start With Mission Value
Prioritize use cases tied to measurable business, delivery, or mission outcomes.
Protect the Data Boundary
Define what data AI tools can touch before selecting vendors or architectures.
Keep Humans Accountable
Use AI to support workflows while retaining trained review and escalation paths.
Document the Controls
Maintain inventories, testing evidence, monitoring plans, and risk decisions.
Most RAG systems are built like search demos.
That is the problem.
They can answer questions. They can summarize documents. They can pull from a knowledge base. They can make enterprise AI feel useful in a week.
Then someone asks the question that matters in GovCon: can this RAG pipeline respect the same access rules, CUI boundaries, audit requirements, and role based controls that already exist in the enterprise?
If the answer is no, the system is not production ready.
For GovCon, secure RAG architecture is the pattern for letting AI use internal knowledge without turning document repositories, vector databases, embeddings, prompts, and generated answers into a new data exposure path.
The goal is simple: let users ask better questions, but do not let AI show them anything they are not allowed to see.
For a broader enterprise comparison of shared indexes, domain separation, tenant stores, delegated retrieval, hybrid brokers, and isolated lanes, use the companion guide to secure RAG design patterns for enterprise data.
Build RAG your security team can actually approve.
GS Consulting helps GovCon and regulated teams design secure RAG architecture across source inventory, CUI boundaries, metadata, vector database security, identity, retrieval controls, private LLM lanes, audit logs, and monitoring.
Request a Secure RAG Architecture ReviewWhat RAG Really Does
RAG stands for retrieval augmented generation. The basic idea is that the system retrieves relevant information from an external source, then gives that information to a language model so the model can generate a better answer.
The original RAG paper described combining a pretrained model with an external memory source accessed by a retriever. The authors found that RAG could generate more specific and factual answers than a model relying only on its internal parameters.
That is why RAG became the standard enterprise AI pattern. A model by itself does not know your contracts, SOPs, CUI handling procedures, proposal history, engineering documentation, policy library, security plans, customer requirements, or program records. RAG gives the model approved context.
But in GovCon, context is not neutral. Context may include CUI, controlled technical information, contract data, proposal language, customer communications, security documentation, legal material, pricing, HR records, or mission related information.
That changes the architecture.
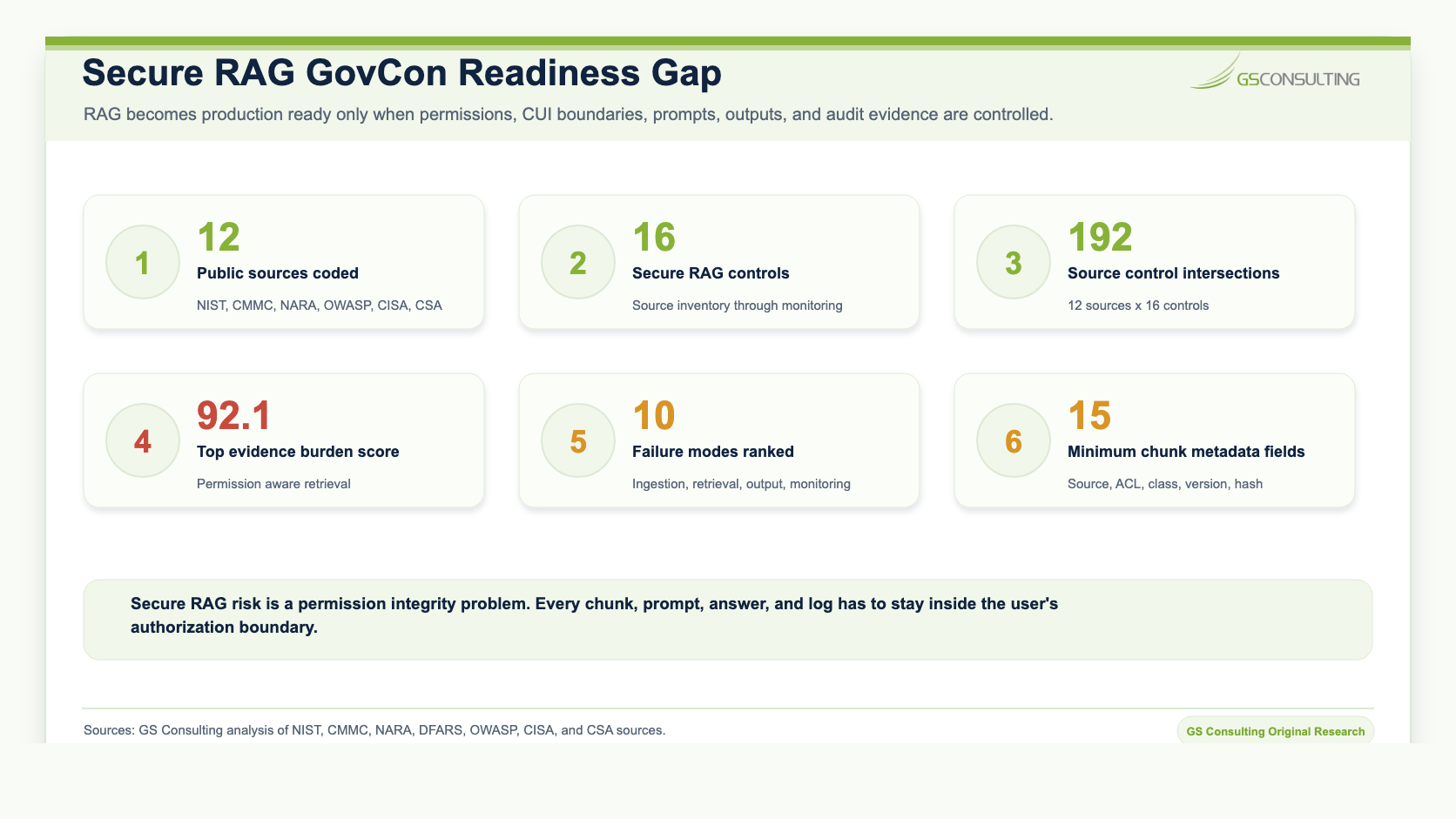
Original Research: The Secure RAG Permission Integrity Index
Original GS Consulting research shows that secure RAG for GovCon is a permission integrity problem, not just a retrieval quality problem.
GS Consulting analyzed public AI governance, cybersecurity, CUI, CMMC, LLM security, and RAG sources against 16 secure RAG architecture controls. The source set included the original RAG paper, NARA CUI materials, NIST SP 800 171, DoD CMMC Level 2 scoping guidance, DFARS 252.204 7012, NIST SP 800 53, NIST AI RMF, NIST Generative AI Profile, OWASP LLM and GenAI risks, CISA, NSA, and FBI AI data security guidance, CISA and NSA agentic AI guidance, and the Cloud Security Alliance AI Controls Matrix.
The scoring model coded 192 source control intersections and calculated a GS Consulting derived Evidence Burden Score using weighted source convergence and RAG specific failure impact. This is a planning metric, not an official NIST, CMMC, NARA, CISA, OWASP, CSA, DFARS, legal, audit, or compliance score.
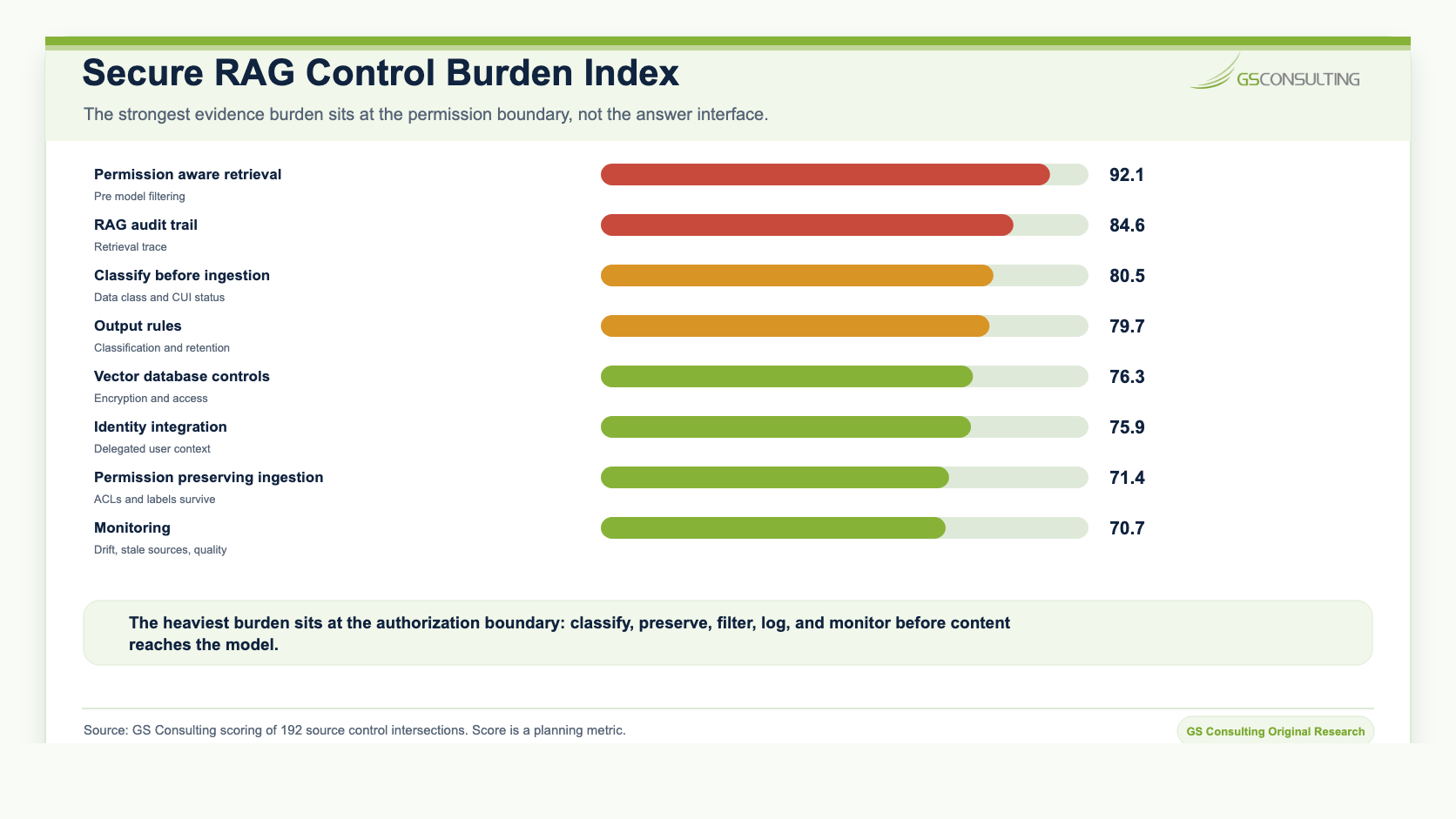
The highest scoring control was permission aware retrieval with filtering before content reaches the model, with an Evidence Burden Score of 92.1. That aligns with the core operating rule for secure RAG: the model should never receive restricted content for an unauthorized user in the first place.
The analysis also showed that the most dangerous RAG failures happen before the answer is generated. Lost permissions during ingestion, broad service accounts, filtering too late, mixed sensitivity indexes, missing chunk metadata, and poor monitoring are architecture failures. They are not prompt engineering problems.
The Main Security Problem
The main security problem in RAG is not that the model might hallucinate. That is one problem. The bigger problem is that the retrieval layer may hand the model information the user should not be allowed to see.
Here is the simple failure pattern.
A contractor indexes a SharePoint library. The library contains public documents, internal policies, proposal content, contract files, and CUI. A user asks a question. The retriever finds the best matching chunks. The model summarizes them. The user gets an answer from documents they could not open directly.
The source document was protected. The AI answer was not.
That is the failure. The user never downloaded the restricted file, but restricted information still leaked through the answer. Secure RAG architecture is designed to prevent that.
CUI Makes This More Serious
GovCon teams cannot treat document retrieval like a generic enterprise search problem. CUI is information that requires safeguarding or dissemination controls under applicable law, regulation, or government wide policy, even though it is not classified. The CUI Registry is the government wide online repository for federal CUI policy and practice, and contractors still need to follow agency specific direction.
That means a GovCon RAG system has to know more than which chunks are semantically relevant. It needs to know who is asking, what contract or program they support, what data category the source belongs to, whether the source contains CUI, whether the user has access to the document, whether the output inherits the source sensitivity, whether the workflow needs logging, whether the answer can be exported, and whether the environment is approved for that data.
If your RAG system cannot answer those questions, it should not touch controlled information.
Secure RAG Is Not Just a Vector Database
A lot of RAG architecture diagrams make the same mistake. They show documents going into embeddings, embeddings going into a vector database, search results going into the model, and an answer coming back.
That is the demo diagram. It is not the GovCon production diagram.
A secure RAG pipeline needs source inventory, document classification, permission preserving ingestion, source ownership, chunk metadata, embedding protection, vector database access control, retriever filtering, prompt controls, output classification, audit logging, human review for high risk workflows, monitoring, and a stop path.
The vector database is only one piece. If the rest of the architecture is weak, the vector database becomes a fast way to leak sensitive knowledge.
OWASP lists vector and embedding weaknesses as a 2025 risk area for large language model and generative AI applications, especially for systems using RAG. OWASP also lists prompt injection and sensitive information disclosure as major risks. That should tell engineers something important: RAG security is core architecture.
1. Start With Source Inventory
Start with the documents. Not the model. Not the vector database. Not the user interface.
For each source, document the business owner, data owner, system owner, data category, CUI status, contract or program association, access model, retention rules, and approved AI use. If no one owns the source, do not index it.
2. Classify Data Before Ingestion
Do not embed documents before classification. That is backward. Classify first.
At minimum, classify documents as public, internal, confidential, CUI, controlled technical information, export controlled, customer restricted, security sensitive, legal sensitive, or restricted. The classification determines where the document can be processed, whether it can be embedded, which environment can store the vector representation, and which users can retrieve it.
3. Preserve Permissions During Ingestion
When a document enters the pipeline, the system should capture access metadata: document ID, repository path, source system, owner, version, sensitivity label, CUI marking, contract or project tag, user groups, access control list, expiration or review date, and other authorization details.
The point is not just to create embeddings. The point is to create embeddings with enough metadata to enforce retrieval rules later. If permissions are lost during ingestion, retrieval cannot reliably enforce them later.
4. Treat Chunk Metadata as the Control Plane
Documents are usually split into chunks. That means metadata needs to follow the chunk.
Useful metadata includes source document ID, repository, source version, chunk ID, section title, page or paragraph reference, classification, CUI status, owner, access groups, program tag, contract tag, customer tag, expiration date, source hash, embedding model version, ingestion timestamp, retention rule, and allowed output lane.
5. Secure the Vector Database
The vector database is not just a technical store. It may contain sensitive representations of sensitive documents. It may also store chunks and metadata with direct sensitive content.
Secure vector database design should include encryption at rest, encryption in transit, role based access, network restrictions, environment separation, separate indexes by sensitivity where needed, metadata filtering, admin access review, audit logs, backup controls, deletion process, embedding refresh process, index rebuild process, and no broad developer access in production.
6. Filter Before Content Reaches the Model
This is the heart of secure RAG. Retrieval must happen in the context of the user.
The system should verify identity, resolve roles and document access, search only approved indexes or filter results by permission metadata, return only chunks the user is allowed to see, and pass only authorized context to the model. Do not rely on the model to hide restricted information. The model should never receive restricted information for an unauthorized user in the first place.
7. Integrate Identity
Secure RAG needs identity integration. This usually means connecting to the enterprise identity provider and respecting group membership, role, project assignment, customer access, contract access, subcontractor status, need to know, and any special restrictions.
Do not build a separate AI permission model that drifts away from the enterprise permission model. AI should inherit and enforce existing authorization boundaries.
8. Use a Controlled Model Lane Where Needed
Not every RAG system needs a private model deployment. But GovCon workflows often need a controlled model environment.
That may mean a private cloud deployment, dedicated tenant, approved enterprise model endpoint, customer controlled environment, restricted network path, no data used for model training, controlled prompt retention, controlled output retention, strong logging, approved regions, or separate environments by data type.
9. Control Prompts and Outputs
RAG prompts contain retrieved source material. Prompts should be treated like part of the data path.
Prompt controls should define what instructions are allowed, what user prompts are logged, what retrieved content is included, whether sensitive data is masked, whether history is retained, whether prompts can be exported, and how prompt injection is handled.
The answer may be sensitive even if it is short. If the answer summarizes CUI, contract terms, security documentation, or customer data, it may need the same handling discipline as the source.
10. Show Sources, Log Activity, and Monitor Drift
For GovCon users, an answer without source references is not enough. The system should show the answer, the sources, what could not be verified, and where human review is required.
Logs should capture user identity, prompt or request, time, repositories searched, documents retrieved, chunks used, documents blocked by permissions, model used, prompt template version, answer generated, source references shown, feedback, exports, workflow actions, and human review where required.
Monitoring should track retrieval accuracy, unauthorized retrieval attempts, no answer rate, wrong source rate, outdated source use, prompt injection attempts, sensitive output events, user override rate, latency, cost, model changes, embedding model changes, index drift, and permission drift.
The Secure RAG Pipeline
A production RAG pipeline should look like this: source systems, classification and owner review, ingestion service, chunking service, metadata enrichment, embedding generation, vector database with access controls, identity aware retriever, policy filter, prompt builder, private or approved LLM endpoint, output classifier, source reference builder, audit logging, human review where required, monitoring, and a stop path.
Notice what is not there: a giant folder dump straight into a vector database.
That is not architecture. That is a future incident.

Common GovCon RAG Failure Points
The biggest failures are predictable.
- Indexing mixed sensitivity content. Public files, contracts, CUI, proposal content, and customer data get indexed together.
- Losing permissions during ingestion. The source system had access controls. The vector database does not.
- Using broad service accounts. The connector can read everything, so user permissions become irrelevant.
- No chunk classification. The document may be mostly general, but one section contains sensitive data.
- No source references. Users get answers but cannot verify them.
- Storing outputs in the wrong place. A sensitive answer lands in a general chat history.
- Treating embeddings as harmless. Embeddings, metadata, and stored chunks may carry sensitive value.
- No monitoring. Six months later, sources are stale, permissions drift, and retrieval quality drops.

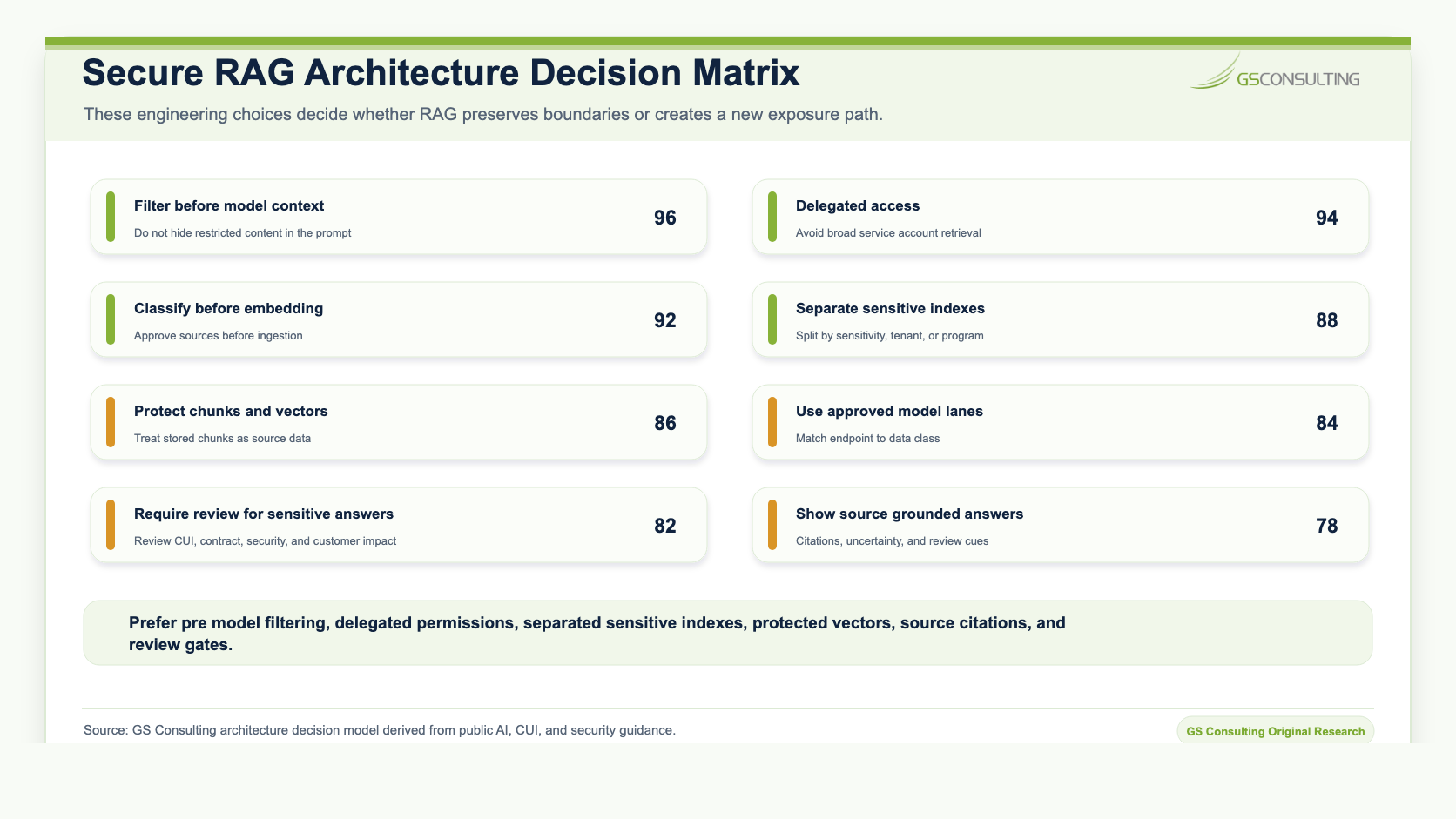
Engineering Decisions That Matter
For software engineers and CTOs, these are the decisions that usually determine whether secure RAG works.
| Decision | Lower control choice | Stronger control choice |
|---|---|---|
| Indexes | One mixed index | Separate indexes by sensitivity, tenant, customer, or program where needed |
| Filtering | Tell the prompt not to reveal restricted content | Filter before unauthorized content reaches the model |
| Connector access | Broad service account | Delegated access or tightly scoped service account with review |
| Chunk storage | Store text without strong controls | Protect chunks, metadata, and embeddings like sensitive source data |
| Model lane | Generic public endpoint | Private, dedicated, or approved enterprise endpoint matched to the data |
| Permissions | Periodic best effort sync | Real time or frequently refreshed checks with drift monitoring |
| Review | Direct answers for all workflows | Human review for CUI, contract, compliance, security, and customer impact workflows |
Secure RAG Checklist for GovCon
Before launching a secure RAG system, ask practical questions.
- What repositories are being indexed?
- Who owns each repository?
- What data categories are inside?
- Does any source contain CUI?
- Are documents classified before ingestion?
- Are permissions captured during ingestion?
- Are permissions enforced during retrieval?
- Does every chunk carry source and sensitivity metadata?
- Is the vector database encrypted and access limited?
- Are indexes separated by sensitivity where needed?
- Does the model run in an approved environment?
- Are prompts and outputs retained, classified, and protected?
- Can data be used for model training?
- Are source references shown?
- Can logs support audit?
- Can the system detect permission failures and stale sources?
- Who can pause the system?
- Who owns ongoing monitoring?

If the team cannot answer these questions, the RAG system is not ready for GovCon production.
How Secure RAG Supports AI Automation
RAG is not just a question answering pattern. It is the knowledge layer for secure AI automation.
A secure RAG system can support contract review, proposal support, CUI handling guidance, policy search, compliance evidence review, SOP guidance, engineering document search, IT help desk support, security playbook retrieval, customer support knowledge, and program knowledge management.
But only if the architecture respects permissions and data boundaries.
This is why RAG connects directly to Secure AI Automation for Regulated Organizations. If AI automation needs internal knowledge, RAG is often the right pattern. If the knowledge is regulated, sensitive, or contract controlled, secure RAG architecture is the difference between a useful system and an uncontrolled exposure path.
What GS Consulting Builds
GS Consulting helps GovCon teams design and build secure RAG architecture that is ready for real enterprise use.
- RAG architecture design and source system review.
- CUI aware data classification and secure ingestion pipelines.
- Permission preserving metadata design and chunk schemas.
- Vector database security, identity integration, and role based access control.
- Document retrieval controls, prompt controls, and output controls.
- Private LLM architecture and approved model environment planning.
- Audit logging, monitoring, evaluation, and human review workflows.
- Production deployment planning and evidence packets.
This is not just model integration. It is custom AI engineering for regulated environments.
The Bottom Line
RAG is the standard enterprise AI pattern because it lets models use internal knowledge.
But in GovCon, internal knowledge is not just content. It is controlled data, contract data, customer data, CUI, security data, and operational knowledge that must stay inside the right boundaries.
A secure RAG architecture has to preserve permissions from source to answer. It has to protect the vector database. It has to run in the right model environment. It has to show sources. It has to log activity. It has to classify outputs. It has to prevent AI from becoming a back door into restricted documents.
The companies that get this right will be able to use enterprise AI safely across document heavy workflows. The companies that skip it will build a very impressive search tool that their security team eventually has to shut down.
Ready to build RAG that respects real enterprise boundaries?
Contact GS Consulting for secure RAG architecture design, CUI aware data controls, vector database security review, and production AI automation planning.
Contact GS ConsultingResearch Sources and Caveats
The Secure RAG Evidence Burden Score, Failure Mode Priority Score, Workflow Readiness Score, and Architecture Decision Matrix are GS Consulting derived planning tools. They are not official NIST, CMMC, NARA, CISA, OWASP, CSA, DFARS, legal, audit, or compliance determinations.
Actual secure RAG readiness depends on the contractor's CUI scope, customer direction, contracts, system architecture, identity provider, repository permissions, CMMC boundary, model and vendor terms, vector database design, logging requirements, data retention obligations, and assessor or customer expectations.
- Retrieval Augmented Generation for Knowledge Intensive NLP Tasks
- National Archives: About Controlled Unclassified Information
- National Archives: CUI Registry
- NIST SP 800 171 Rev. 3
- NIST SP 800 53 Rev. 5
- OWASP Top 10 for LLM Applications
- CISA: Securing AI Data guidance announcement
- Cloud Security Alliance AI Controls Matrix
Frequently Asked Questions About Secure RAG Architecture
What is secure RAG architecture?
Secure RAG architecture is a controlled retrieval augmented generation design that preserves source permissions, classifies data before ingestion, secures vector storage, filters retrieved content by user authorization before it reaches the model, classifies outputs, shows sources, logs activity, and monitors drift.
Why is RAG risky for GovCon organizations?
RAG can be risky for GovCon organizations because it may retrieve, summarize, or expose CUI, contract data, security documentation, proposal content, or customer information unless permissions, CUI boundaries, model environment, logging, and output handling are designed correctly.
Should a GovCon RAG system use a private LLM?
Not every RAG system needs a private LLM, but GovCon workflows involving CUI, sensitive contract data, customer information, or security documentation often need a controlled model environment, approved tenant, restricted network path, retention controls, and clear vendor terms.
What is the most important secure RAG control?
The most important control is permission aware retrieval before the model receives context. The model should never receive restricted content for a user who is not authorized to see it.
Related Reading
- Private LLM and Secure RAG hub
- What Is a Private LLM?
- Private LLM Deployment Options
- Secure AI Automation for Regulated Organizations
- Managing AI Vendor Risk in Regulated Industries
- Secure AI Architecture Patterns for Enterprises
- Preventing CUI Leakage in LLMs
- AI Access Controls and Permission Design
- Data Classification Before AI Automation
- AI Automation for Sensitive Data Workflows
- AI Audit Trails and Activity Logging
- How DoD Contractors Can Use AI Without Putting CUI at Risk