Enterprise AI Strategy | | 24 min read
Establishing Guardrails for Enterprise Generative AI

Key Takeaways
Generative AI guardrails make policy enforceable
Policy Is Not a Control
The model reads prompts, not policy PDFs. Guardrails enforce rules at input, data, output, action, and logging layers.
Liability Moves Fast
A customer-facing model can create binding commitments, expose confidential data, or publish fluent falsehoods before leadership sees the incident.
Evidence Matters
Regulated teams need artifacts that prove what the AI touched, what was blocked, what was approved, and who owns review.
A generative AI model with no guardrails is a confident stranger you have given access to your data and pointed at your customers. It will answer any question, including the ones it has no business answering. It will state things that are wrong with total fluency. It will repeat back whatever someone tricks it into saying. And it will do all of this in your name, on your brand, sometimes in a way a court will hold you to. The question is never whether an ungoverned model will say or do something it should not. It is what catches it before that reaches a customer, a regulator, or the public.
This is not a hypothetical risk anymore. Stanford researchers found that even purpose-built legal AI tools hallucinate on something like 17 to 33 percent of queries, and general-purpose models get legal questions wrong well over half the time. Roughly 11 percent of the data employees paste into tools like ChatGPT is confidential. A Canadian tribunal has already held an airline responsible for a refund policy its own chatbot invented, rejecting the argument that the bot was a separate entity. And while surveys show around 75 percent of organizations have some form of AI governance, only about 12 percent describe it as mature. Most companies have written a policy. Far fewer have built the enterprise generative AI guardrails that make the policy real.
This article is about those controls, the enterprise generative AI guardrails that sit between a generative model and the harm it can cause. Guardrails are not a single safety switch or a content filter you turn on. They are layers: what you let into the model, what you let out, what data it can reach, what actions it can take, and what record you keep of all of it. Get the layers right and generative AI becomes a tool you can defend deploying in a regulated environment. Skip them and you are not running an AI program; you are running an unmanaged liability that happens to be useful.
The Core Problem: The Model Will Say and Do What You Don't Stop
The reason guardrails matter is structural, not a matter of picking a better model. A generative model is built to produce a plausible response to whatever it is given. It does not natively know what is confidential, what is true, what is allowed, or what it is authorized to do. Those are judgments the model cannot reliably make on its own, which means they have to be enforced around it. Without that enforcement, the model's default behavior is to be helpful in exactly the ways that get an enterprise in trouble.
Three failure patterns follow from deploying a model without layered controls. The first is leakage in: employees paste confidential data into prompts, and if the model runs in a vendor environment, that sensitive information has now left your control, where it may be retained or used to train future models. The second is garbage out: the model produces something false, unsafe, or non-compliant with total confidence, and because it sounds authoritative, a human passes it along as fact. The third is unbounded action: as models gain the ability to call tools and take steps, an ungoverned one can act, send, commit, or change something, with no approval gate and no record.
None of these is a sign of a bad model. They are the predictable result of running a capable model with nothing in front of it. They are exactly what layered guardrails exist to catch, and exactly what an acceptable-use policy with no technical enforcement behind it does nothing to stop.
Where Generative AI Actually Goes Wrong
Not every risk is equally likely or equally damaging. Knowing which failure modes dominate tells you where to build first. GS Consulting scored the failure modes that most often turn a helpful generative model into a legal, security, or brand liability, mapped against the OWASP Top 10 for LLM Applications.
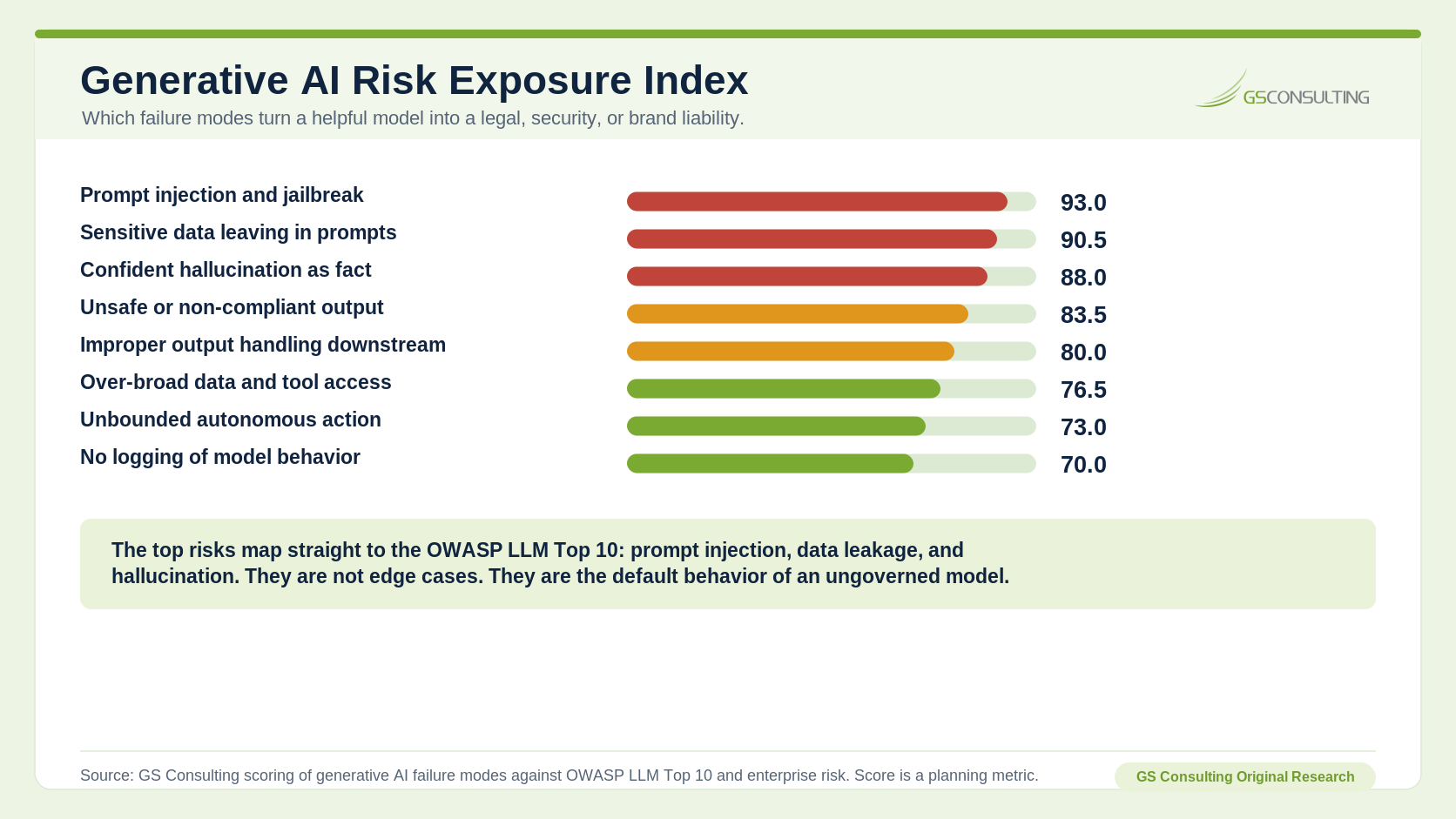
Prompt injection and jailbreak ranks first because it is the failure mode unique to language models and the hardest to fully eliminate: a user, or a piece of content the model reads, can override its instructions, and research has shown jailbreak techniques succeeding against frontier models a majority of the time. It sits at the top of the OWASP LLM Top 10 for a reason. Sensitive data leaving in prompts ranks second because it is the most common and the easiest to do by accident; every confidential document pasted into an ungoverned tool is a potential exposure. Confident hallucination ranks third because it is the one that fools people: a fabricated fact stated fluently is far more dangerous than an obvious error, which is how fake legal citations keep ending up in court filings.
A few numbers worth putting in front of a risk committee:
- 17-33% — hallucination rate of purpose-built legal AI tools on legal queries, per Stanford RegLab research.
- 58-88% — hallucination rate of general-purpose models on legal questions, in the same research.
- ~11% — share of data pasted into ChatGPT that is confidential, per Cyberhaven.
- 75% vs 12% — organizations with AI governance versus those describing it as mature, per PwC.
- C$812.02 — the refund a tribunal ordered an airline to honor after its chatbot invented a policy, in Moffatt v. Air Canada.
(The Generative AI Risk Exposure Index is a GS Consulting derived planning metric. It is not a security audit or a model evaluation.)
Deploying generative AI without controls you can defend?
GS Consulting helps CISOs, legal teams, and IT leaders build enterprise generative AI guardrails: input filtering, data-access scoping, output grounding and safety checks, action approval gates, logging, and the evidence that proves the controls work.
Request a Generative AI Guardrail AssessmentWhat No Guardrails Actually Costs
The cost of an ungoverned model is not theoretical, and it is not just embarrassment. It shows up as binding commitments, exposed data, published falsehoods, and decisions you cannot defend. GS Consulting scored the liabilities an enterprise incurs when a model speaks or acts with no control in front of it.
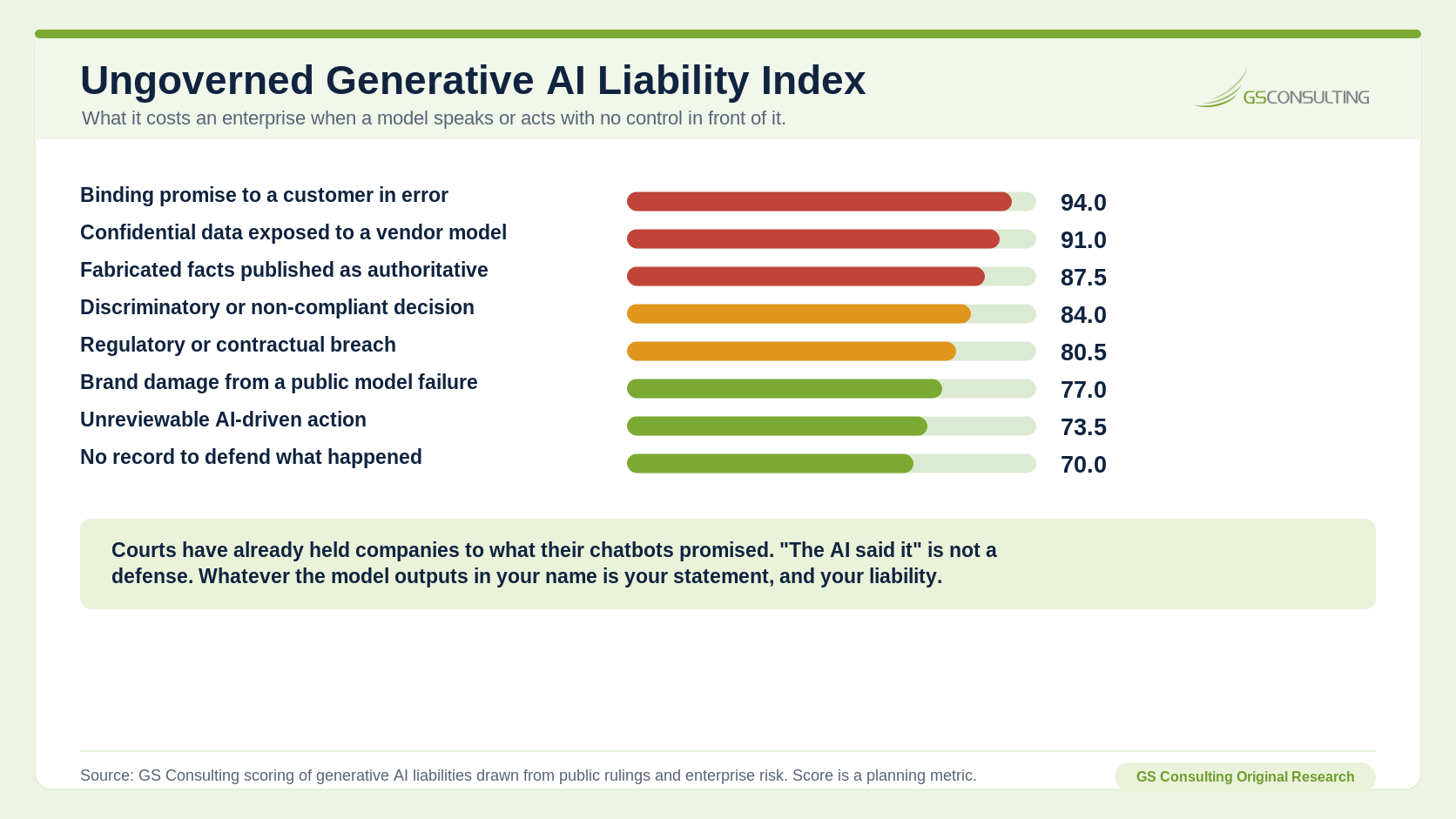
The worst liability is a binding promise made in error. When a customer-facing model commits your organization to something, a price, a policy, a refund, that commitment can be enforceable, and "the AI said it, not us" has already failed as a defense in court. Close behind is confidential data exposed to a vendor model, because once sensitive information enters a third party's environment through a prompt, you have lost control of it in a way that can trigger regulatory and contractual obligations. Fabricated facts published as authoritative ranks third, because a hallucination that reaches a filing, a report, or a customer carries the full weight of an official statement from your organization.
Notice the through-line. The damage is rarely that the model was unintelligent. It is that the model's output became your statement, your commitment, or your exposure with nothing in between to catch it. Whatever a generative model produces in your name is your liability, and the only thing that changes that is a guardrail that reviews, grounds, or blocks the output before it lands. (The Ungoverned Generative AI Liability Index is a GS Consulting derived planning model, not a legal risk determination.)
The Wrong Way to Govern Generative AI
The wrong way is to write a policy and call it a control.
It looks responsible from the outside. Legal and IT draft an acceptable-use policy: do not paste confidential data, verify AI output, do not rely on it for regulated decisions. The policy is circulated, everyone clicks "acknowledge," and the organization considers generative AI governed. Then the actual behavior diverges immediately. People paste confidential data because it is the fastest way to get a useful answer. They forward fluent-sounding output without verifying it because it looks right. A customer-facing bot says something the policy never anticipated. None of the policy's good intentions touched the model, because a policy is a statement of what should happen, and a guardrail is a control that makes it happen. The gap between them is precisely the gap between the 75 percent of organizations with governance and the 12 percent whose governance is mature.
This is the trap: governance that lives in a document instead of in the system. The model does not read the policy. It reads the prompt. If the only thing standing between a confidential document and a vendor's training set is an employee remembering a rule they clicked through months ago, you do not have a guardrail. You have a hope. And hope is exactly what fails at scale, quietly, until an incident makes the gap visible at the worst possible moment.

The Right Way: Layer the Guardrails Around the Model
The right way treats guardrails as layers a prompt and a response must pass through before they reach a user or take an action, with enforcement built into the system rather than written into a policy.

- Gate 1Filter input.
Inspect what goes into the model for prompt injection, abuse, and attempts to override its instructions. This is the first line against the top OWASP LLM risk, and it has to run on both user input and any external content the model ingests.
- Gate 2Scope data.
Give the model least-privilege access to data, scoped to exactly what the use case requires. A model that can reach everything can leak everything; scoping limits the blast radius of any single failure.
- Gate 3Ground the response.
Require the model to answer from approved, retrievable sources and cite them, rather than generating freely from memory. Grounding is the most effective single control against confident hallucination.
- Gate 4Check output.
Inspect the response against safety, policy, and accuracy rules before it leaves the system. This is the layer that catches the unsafe or non-compliant answer in the act, instead of after a human has already forwarded it.
- Gate 5Gate actions.
For any high-impact action the model can take, sending, committing, changing, require human approval. Autonomous capability without an approval gate is how an AI takes an action no one authorized and no one can undo.
- Gate 6Handle output.
Mark and route AI output according to its sensitivity, the same way you would any other content the organization produces. Output derived from sensitive data carries that sensitivity forward.
- Gate 7Log everything.
Record prompts, responses, and actions with enough detail to reconstruct what happened. An AI behavior you cannot trace is one you cannot defend, improve, or even prove occurred.
- Gate 8Monitor drift.
Watch for new failure patterns over time. Models, prompts, and attack techniques change, and guardrails that were sufficient at launch can quietly stop catching what they used to.
A Little Math on the Cost of Skipping Guardrails
The economics of guardrails are lopsided, which is what makes skipping them such a bad trade.
Consider the exposure side. A single customer-facing model handling thousands of conversations a day will, with no grounding or output check, produce some rate of confident errors, call it even a fraction of a percent. Across thousands of interactions, that is dozens of wrong answers a day going out under your brand, any one of which could be the binding promise or the published falsehood that becomes a claim. Now add the data side: with around 11 percent of pasted content being confidential and no input scoping, every day of ungoverned use is a steady trickle of sensitive data leaving your control. The expected cost is not a single dramatic event. It is a constant, compounding probability of an expensive one, multiplied by how much you use the model.
Now weigh the control side. The core guardrails, input filtering, data scoping, grounding, output checks, an approval gate, and logging, are largely build-once, run-everywhere. You implement them around the platform, and every use case inherits them. The marginal cost of protecting the next use case is small once the layers exist. So the trade is a bounded, one-time engineering and process investment against an unbounded, recurring liability. The reason organizations get this wrong is not that the math is hard. It is that the cost of skipping guardrails is invisible right up until the incident, and the cost of building them is visible on day one.
That is the whole case. The model is roughly as useful with guardrails as without. The difference is whether its inevitable failures are caught by a control or discovered by a customer, a regulator, or a court.
Guardrail Moves, Ranked
Guardrails are a set of moves, and they are not equally valuable. GS Consulting scored the major guardrails on how much risk they remove, how feasible they are, and how little friction they add.

The highest-scoring move is keeping sensitive data out of vendor prompts, because it stops the most common exposure at the source and is largely an architecture and routing decision rather than an ongoing effort. Filtering for prompt injection ranks just below, because it addresses the top OWASP LLM risk and the one most likely to be actively exploited. Grounding answers in approved sources rounds out the top tier, because it is the single most effective control against the hallucination that fools people. The lower-ranked moves, least-privilege scoping and drift monitoring, are essential to a mature program and reduce the blast radius and the long-term decay of your controls, but they deliver their value on top of the high-impact layers rather than instead of them. (The Generative AI Guardrail Decision Matrix is a GS Consulting derived planning model, not a product evaluation.)
The Evidence: What Guardrails Produce
In a regulated environment, having guardrails is not enough; you have to be able to prove they exist and work. GS Consulting frames the output of a guardrail engagement as an evidence packet, because legal, security, and a regulator will each ask for a different part of it to confirm the model is actually controlled.

This packet turns "we have an AI policy" into a controlled system you can defend. It shows what the model touches, what is allowed, how input is filtered, how data is scoped, how answers are grounded, how output is checked and handled, how actions are gated, what is logged, how failures are monitored and handled, and who keeps it current. The PwC finding that 75 percent of organizations have governance but only 12 percent are mature is, in practical terms, the difference between having a policy and being able to produce this packet. If you cannot assemble it, your generative AI is governed on paper and ungoverned in production.
The First 90 Days
If you are a CISO, legal leader, or IT executive whose organization is using generative AI faster than it is controlling it, here is a realistic sequence.
- Weeks 1-2Inventory and route.
Inventory where generative AI is actually being used and what data it touches. Shut down the most direct exposure by routing sensitive use cases away from vendor models that retain or train on prompts.
- Weeks 3-6High-impact layers.
Implement input filtering for injection, data-access scoping, and grounding for any use case that produces factual output.
- Week 7+Output checks and gates.
Add output checks against your safety and policy rules and put human approval gates in front of any action the model can take.
- Final stretchLogging and incident prep.
Turn on logging across all AI activity, stand up monitoring for new failure patterns, and write the incident and rollback plan for when a guardrail fails.
Ninety days does not produce a fully mature program, but it closes the exposures that cause the headline incidents: confidential data leaving in prompts, injection going undetected, hallucinations shipping ungrounded, and actions taken with no approval or record. The rest is hardening and monitoring on top of a system that is already defensible.
Common Mistakes
The mistakes here are consistent. Organizations write an acceptable-use policy and treat it as a control, when the model never reads the policy. They rely on a single content filter and call it a guardrail, when guardrails are inherently layered. They focus entirely on input ("don't paste secrets") and ignore output, so hallucinations and unsafe answers ship unchecked. They give models broad data and tool access for convenience, maximizing the blast radius of any failure. And they deploy customer-facing or action-taking AI with no human gate and no logs, so the first sign of a problem is an external one.
Every one of these is the same root error: treating generative AI governance as a document instead of a system. A guarded model has enforcement built in at every layer; a governed-on-paper model has a rule somebody clicked through and a confident stranger doing whatever the prompt asks.
How This Fits a Secure Enterprise AI Strategy
Guardrails are where a Secure Enterprise AI Strategy meets the model itself. The strategy decides which generative AI use cases are worth pursuing and what risk the organization will accept; guardrails are the technical layers that hold the model to those decisions in production, so the strategy is enforced rather than merely stated. Without them, a secure AI strategy is a set of intentions that an ungoverned model routinely violates.
They are also the operational core of a broader governance program, the subject of Enterprise AI Governance Frameworks. A governance framework defines the roles, policies, and accountability for AI across the organization; guardrails are how those policies become enforced controls instead of aspirations. The framework says what must be true. Guardrails are what make it true at the moment a prompt is submitted or a response is returned, which is the only moment that actually counts.
The Bottom Line
A generative model with no guardrails is not a slightly risky tool. It is a confident stranger with access to your data and a direct line to your customers, and its default behavior, leaking what it is given, stating falsehoods fluently, doing whatever a prompt asks, is exactly the behavior that creates legal, security, and brand liability. The research is blunt about it: high hallucination rates even in purpose-built tools, confidential data routinely pasted into vendor models, and courts already holding companies to what their chatbots said.
Guardrails are what stand between the model and the harm, and they are layers, not a switch: filter the input, scope the data, ground and check the output, gate the actions, and log all of it. Most organizations have a policy; far fewer have the controls, and the gap between those two is where the incidents happen. Build the layers once around your platform and every use case inherits protection you can actually defend. Skip them and you are running an unmanaged liability that happens to be useful, right up until it is not. Put the guardrails in front of the model before it speaks or acts in your name, not after it already has.
Ready to turn your AI policy into controls you can defend?
GS Consulting helps CISOs, legal teams, and IT leaders build and prove enterprise generative AI guardrails, from input filtering and data scoping through output grounding, action gates, logging, and evidence.
Request a Generative AI Guardrail AssessmentResearch Sources and Caveats
This article draws on public 2024 through 2026 sources on generative AI risk and governance, including the Stanford RegLab and HAI studies on legal AI hallucination rates, Cyberhaven research on confidential data entering AI tools, the OWASP Top 10 for LLM Applications (2025), the NIST AI Risk Management Framework and its Generative AI Profile (NIST AI 600-1), the PwC and related surveys on AI governance maturity, published rulings including Moffatt v. Air Canada, and reporting on jailbreak and prompt-injection research.
The Generative AI Risk Exposure Index, the Ungoverned Generative AI Liability Index, and the Generative AI Guardrail Decision Matrix are GS Consulting derived planning tools. They are scoring models built to help CISOs, legal leaders, and IT executives prioritize guardrail work. They are not security audits, model evaluations, or legal determinations, and the scores should be treated as planning inputs rather than certified measurements. Hallucination rates, data-exposure figures, and governance-maturity percentages are drawn from specific studies and surveys and reflect those samples, not a universal measurement. Nothing here is legal advice; confirm specific obligations and liabilities against current law and your contracts.
Frequently Asked Questions About Enterprise Generative AI Guardrails
Isn't choosing a safer, better model enough?
No. A better model hallucinates less and resists jailbreaks better, but it still does not natively know what is confidential, what your policies allow, or what it is authorized to do. Those are enforced around the model, not inside it. Model choice reduces the rate of failures; guardrails are what catch the ones that still happen and keep them from reaching a customer or a regulator.
Will guardrails make the AI slow or useless?
Well-designed guardrails add little perceptible latency and barely change the experience for legitimate use. What they change is the failure cases: a blocked injection attempt, a grounded answer instead of a fabricated one, an approval step before a high-impact action. Users who are doing normal work mostly do not notice them; the value shows up entirely in the failures they prevent.
We already have an acceptable-use policy. Isn't that governance?
It is the start of governance, but a policy is not a control. The model does not read your policy; it reads the prompt. Real guardrails enforce the policy in the system, by filtering input, scoping data, checking output, and gating actions. The gap between having a policy and having enforcement is exactly the gap between the organizations with governance and the few with mature governance.
Is hallucination really a guardrail problem or just a model limitation?
Both, but you control it with guardrails. You cannot fully eliminate hallucination through model choice, but you can dramatically reduce its impact by grounding answers in approved sources with citations and checking output before it ships. That turns "the model might be wrong" into "the system shows its sources and flags answers it cannot ground," which is the difference between a research aid and a liability.
Who should own generative AI guardrails?
It is a shared responsibility, which is why it often falls through the cracks. Security owns the technical controls and logging, legal owns the policy and liability questions, and IT or an AI platform team owns the implementation and monitoring. The key is a single accountable owner for the guardrail program overall, with a defined review cadence, rather than three teams each assuming another has it covered.
Related Reading
- Secure Enterprise AI Strategy
- AI Agent Lifecycle Management and Oversight
- Shifting from Point Solutions to Unified AI Platforms
- Enterprise AI Governance Frameworks for GovCon
- AI Governance Framework for Regulated Organizations
- Managing AI Vendor Risk in Regulated Industries
- Developing a Phased Secure AI Adoption Roadmap
- Preventing CUI Leakage in LLMs
- AI Access Controls and Permission Design
- AI Audit Trails and Activity Logging